前面說完了我們評估新工具的歷程,接下來就要開始實作啦!
其實如果對 dbt 不是很熟悉的人,或許前幾篇前情提要,更適合在整個系列的最後回頭來看。
要把所有的 sql code 搬移至另一個工具來部署,感覺有點像是搬家跟裝潢的概念。
首先我們按照 dbt 的指引,把開發環境設置完畢(官方文件),把新家硬裝的部分打理打理,才好入住。
這個環節大致會包含與 BigQuery 的互動,密鑰、正式與測試環境的設置,上一章提到的 staging, intermediate, mart 等等的資料集建立好。
接著再來布置軟裝。
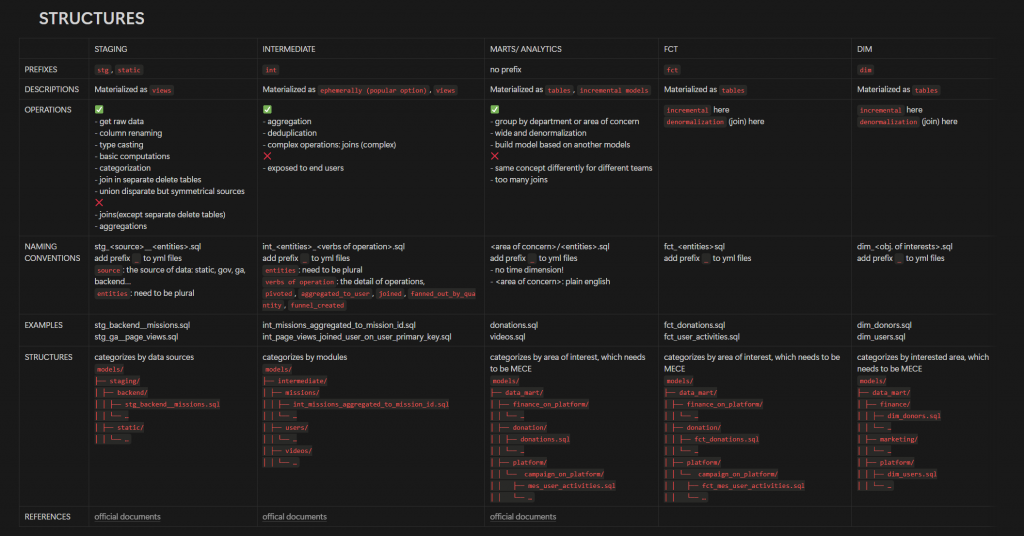
按照官方文件針對各個層級的資料集應該要做什麼樣的處理,套用於我們平台的資料,讓所有開發人員都有共識,後續在 code review 時有一個參照的標準。
其中,我覺得最困難的一個環節是命名的規則(想不到吧!)
文件說的 plural,什麼時候要複數、要複數在哪裡、動詞要用哪個,使用者所在的地區是 user_locations 還是 users_locations?講師的英文要統一為哪個單字?為了這些討論了大半天都是常有的事。
雖然看起來雞毛蒜皮,但統一這件事情,絕對是重中之重,下一篇再花篇幅討論。
最後就是勞力活啦!把東西搬來新家。
首先先盤點過去的 SQL code 中哪些還有在使用,沒在用的就直接忽略,有在使用的就先照搬過來,將原先的 project_id.dataset_id.table_id改成 dbt 支持的語法 {{ ref(table_id) }},table_id 依照 dbt 的規則來做調整,純純的搬運工,可以邊搬邊看點影片的那種(🤫)
呃嗯,其實搬的時候需要思考蠻多事情的,像是 intermediate 重視重用性,一邊搬運時,一邊感受哪些資料處理一再被使用到,是否可以拉出一個 model 專門來做這個轉換?這樣所有的下游表都可以借來用用。
理論上 sql model 跟 yml file 應該是同步寫的,不過老實坦白,只有近期新開發的 pipeline 有做到這件事情(在 pipeline 建立完成時,必須同時將文件跟測試一起部署)。當時為了快速完成大量搬運,我們把 yml file 的文件工暫時放了放,具體來說,搬運去年就完成了,文件慢慢補上,直到最近才好不容易把 mart 的部分補齊了,方便跟其他業務單位溝通。
搬運陸續完成後,我們也才在開發環節上進行優化。
首先是聽到 dbt cloud 有可能按模型計價的風聲,我們就將 dbt core 建起來,並且搭配 vscode 中的 dev container,讓所有開發人員在將 repo clone 下來之後可以馬上執行與開發,不需要額外安裝跟設置一堆有的沒的(這個也是後續會再寫一篇~)
另外則是在 Github Action 上部署簡單的 CI/CD 流程,當開發人員寫完推 PR 上去會測試 pipeline 有沒有什麼問題,畢竟雖然本地端也可以直接叫 API 執行,但遇過太多說沒問題包君滿意隔天爆一堆 error 的冏境(包含我自己XD),還是加上一道保險才是。
這大概就是整個導入的過程啦!接下來的甘苦談且聽我娓娓道來吧~

